聚类分析字符串数组
对多个字符串进行聚类分析旨在根据它们之间的相似度将这些字符串划分成若干个类别,使得同一类别内的字符串彼此相似度高,而不同类别间的字符串相似度低
小结
- 数据要清洗。清洗的足够准确,可能不需要用聚类分析了
- 数据要多,聚集点要少,点阵就集中
步骤 1: 数据预处理
标准化:统一字符串的大小写、去除无关字符(如标点符号、空格等)。
步骤 2: 特征提取
-
词频统计:对于每个字符串,统计其包含的词汇表中词语的出现次数,形成一个词频向量。
-
TF-IDF:除了词频统计,还可以使用TF-IDF(Term Frequency-Inverse Document Frequency)值作为特征。TF-IDF考虑了词语在文档集合中的重要性,对频繁出现但无区分度的词语给予较低的权重。
-
词嵌入(Word Embeddings):使用预训练的词嵌入模型(如Word2Vec、GloVe或BERT)将每个词语转换为固定长度的稠密向量,然后对每个字符串中所有词语的向量取平均(或加权平均、最大池化等)得到字符串的向量化表示。
步骤 3: 应用聚类算法
选择聚类算法:如K-means、DBSCAN、谱聚类、层次聚类等。选择时需考虑数据特性、所需聚类形状(如球形、任意形状)、是否需要预先指定聚类数量等因素。
运行聚类:将提取的数值特征作为输入,运行所选聚类算法。对于某些算法(如K-means),可能需要多次尝试以确定最优聚类数量(如通过轮廓系数、肘部法则等评估指标)。
步骤 4: 结果解读与评估
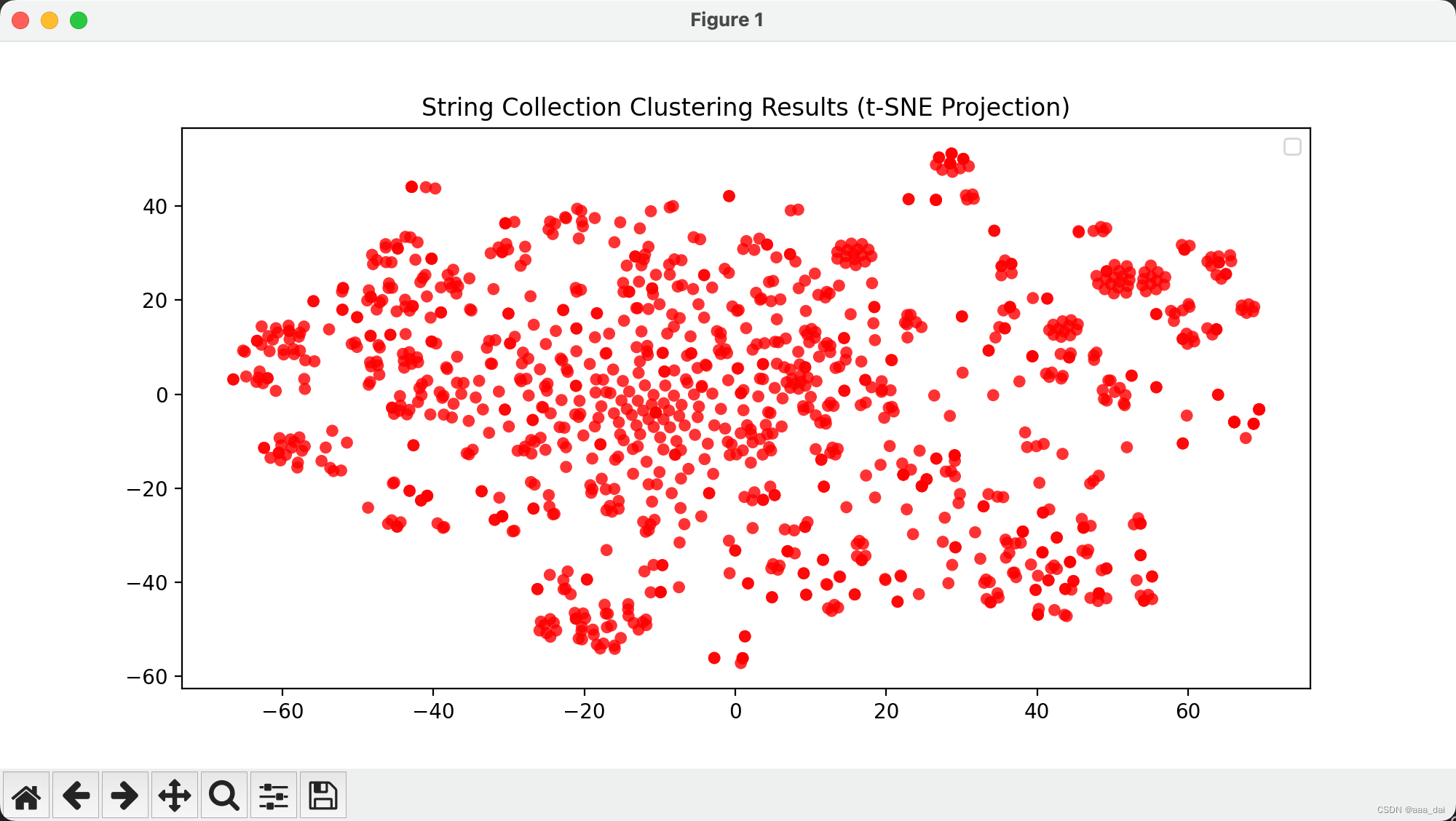
可视化:对于较小的数据集,可以使用散点图、热力图、树状图等可视化聚类结果。
主题分析:分析各聚类中心(或代表性样本)的特征,总结聚类主题或类别描述
code (K-means)
import json
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
from sklearn.compose import ColumnTransformer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.manifold import TSNE
def compute_string_length(s):
return np.array([len(text) for text in s]).reshape(-1, 1)
def clean_data(data):
data = [s.replace('"', ' ') for s in data]
data = [s.split(']')[-1] for s in data]
data = [s.split('】')[-1] for s in data]
data = [s.lower() for s in data]
return data
def analyse(inputs: list[str], n_clusters: int = 10):
preprocessed_strings = clean_data(inputs)
preprocessed_strings = [[text] for text in preprocessed_strings]
# 使用 TF-IDF 向量化文本
feature_vectors = TfidfVectorizer(stop_words='english')
tfidf_transformer = ColumnTransformer([
('tfidf', feature_vectors, 0), # 对文本列进行 TF-IDF 向量化
# ('length', FunctionTransformer(compute_string_length, validate=False), 0) # 计算字符串长度
], remainder='passthrough') # 其他列原样传递
# 将数据转换为 TF-IDF 向量和字符串长度的组合
tfidf_matrix = tfidf_transformer.fit_transform(preprocessed_strings)
# Step 3: K-Means
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
cluster_labels = kmeans.fit_predict(tfidf_matrix)
output = {}
for i, v in enumerate(cluster_labels):
if v not in output:
output[v] = {"name": [], "count": 0, "key": int(v)}
output[v]["name"].append(inputs[i])
output[v]["count"] += 1
sorted_dd_list = sorted(list(output.values()), key=lambda x: x['count'], reverse=True)
with open("a.json", "w") as f:
f.write(json.dumps(sorted_dd_list, ensure_ascii=False))
# Step 4: 可视化 - 使用 t-SNE 和 matplotlib
tsne = TSNE(n_components=2, random_state=42, perplexity=4)
tfidf_matrix_2d = tsne.fit_transform(tfidf_matrix.toarray())
plt.figure(figsize=(10, 5))
for i in range(n_clusters):
mask = (cluster_labels == i)
plt.scatter(
tfidf_matrix_2d[mask, 0],
tfidf_matrix_2d[mask, 1],
c="red",
label="",
alpha=0.8,
edgecolors='none'
)
plt.legend()
plt.title('String Collection Clustering Results (t-SNE Projection)')
plt.show()
if __name__ == '__main__':
demo = [
"Concealer covers face with spots, pimples, dark circles, eyes and tears",
"【 Import day price 】Makeup revolution Concealer cover the face spots, acne, black eye circles, tears do not take off makeup",
"Makeup revolution Concealer Party sister K sister recommended to cover acne dark circles lasting moisturizing moisture",
"Concealer covers face with spots, pimples, dark circles, eyes and tears",
"Makeup revolution Concealer Party sister K sister recommended to cover acne dark circles lasting moisturizing moisture",
"Makeup revolution Concealer Party sister K sister recommended to cover acne dark circles lasting moisturizing moisture",
"Omorovicza Ultra Tonic Oil 30ml",
"【 Mia Exclusive 】MZ SKIN 2% hyaluronic Acid Filling Lip Care 3ml",
"Mz Skin Perfect Repair Mask 5 pieces/box",
"NAPIERS Micro Silver Deep Cleansing Mask 100ml canned skin care products clean and soften",
"【 Pre-sale 】MZ SKIN 2% hyaluronic Acid Filling Lip Care 3ml", "Omorovicza Body Massage Oil 100ml",
"Omorovicza Midnight Wake Up Inception Essence 2ml", "MZ SKIN 5-Day White Rejuvenating Ampere 2ml*2",
"MZ SKIN10% Vitamin C Whitening Serum 5ml", "Mz Skin 5-Day White Rejuvenating Ampere 10*2ml",
"Mz Skin Perfect Repair Mask sheet"
]
analyse(demo, 5)